
历时7年,特斯拉自动驾驶写了一篇逆袭爽文
历时7年,特斯拉自动驾驶写了一篇逆袭爽文
特斯拉自动驾驶的重大彩蛋出现了。
国外黑客大神 GreenTheOnly 在特斯拉 FSD Beta 的代码中发现了一段隐藏代码。据了解,这段代码可以开启一个全新的模式「Elon Mode」(埃隆模式,代码以马斯克名字命名)。

如果车辆时速在 60km/h 以下,开启这一模式,车辆可以实现 L3 级自动驾驶,无需双手把持方向盘。
可以说,特斯拉在技术上已经有能力实现 L3 级自动驾驶。只是,目前其仍没有拿到政府的相关批准。
在自动驾驶领域,特斯拉一骑绝尘。
但是,领先地位的铸就并非朝夕。
复盘特斯拉自动驾驶发展历程,实际上不亚于看了一篇逆袭「爽文」。即使是特斯拉,也经历了从落后,到追赶超越,再到称王加冕,自我超越的五个时期。
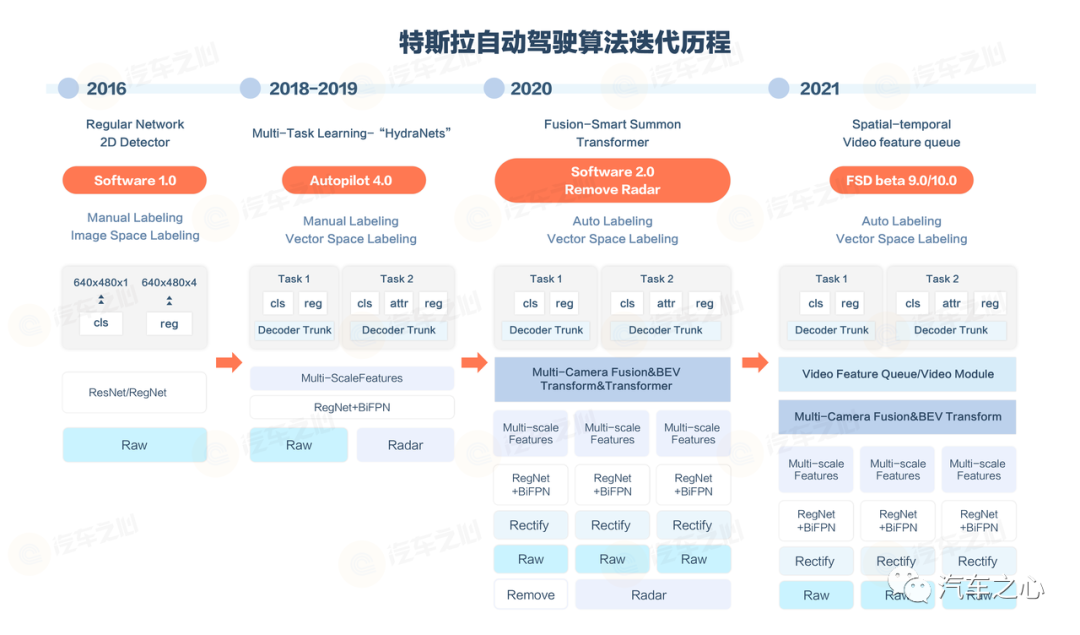
2016 年,在 Mobileye 首先官宣「分手」后,特斯拉便开始自研算法。期间有一段时间,其算法表现甚至不如 Mobileye。
直到 2020 年,重构算法后,特斯拉才确立了行业领头羊的地位。
在这一时期涌现的 BEV、Transfomer、自动标注等技术,现如今已经成为如今行业普遍延用的技术路线。
但特斯拉并未止步,又对算法进行了升级,比如时序信息的加入,升级到占用网络。
自始至终,特斯拉追求的就不是「武林第一」的头衔。
特斯拉的目标只有一个:在纯视觉方案下,如何用算法刻画真实的物理世界,以实现自动驾驶。
总结来看,坚持视觉方案,特斯拉从「第一性原则」出发,针对算法问题进行持续迭代,使算法更趋向于理解真实世界。
01
自研算法诞生前夜,
特斯拉与 Mobileye 分手
2016 年 5 月 7 日,一场发生于美国的车祸引起了全球的关注。
一辆 Model S(2015 年款)在使用 Autopilot 状态下,拦腰撞向了一辆垂直方向开来的白色挂车,事故导致了一人死亡。
彼时,这起事故被媒体冠以「全球首宗自动驾驶致命事故」的标题经大肆报道。
在铺天盖地的报道之下,特斯拉的 Autopilot 成了众矢之的。
特斯拉和 Mobileye 的合作开始于2014 年。
2014 年 10 月,特斯拉发布第一代硬件 Hardware 1.0,软硬件均由 Mobileye 提供,自动驾驶芯片是 Mobileye 的 EyeQ3。
而在上述事故发生的两个月后,2016 年 7 月,Mobileye 宣布了和特斯拉终止合作。供应商抢先声明双方合作破裂,这在汽车市场来说颇为罕见。
对于分手原因,彼时双方各执一词。
在特斯拉看来,Mobileye 的黑盒模式是双方分手的原因所在。
特斯拉曾在一份文件中直言:黑盒模式之下,Mobileye 难以跟上特斯拉产品的发展步伐。
而 Mobileye 则表示:因为特斯拉的自动驾驶功能「超过了安全的底线」,因此才终止了双方的合作。
实际上,双方的分手早有预兆。
2015 年,特斯拉就开始布局自研自动驾驶软硬件,Mobileye 被弃用只是时间问题。
2015 年 4 月,特斯拉组建了基于计算机视觉感知的软件算法小组 Vision,准备自研软件。
同年,特斯拉还从 AMD 挖来了传奇芯片设计师 Jim Keller。随后,在 2016 年,特斯拉开始组建芯片研发团队,并由 Jim Keller 担任 Autopilot 负责人。
和众多俗套的情爱故事一样,与 Mobileye 分手之后,特斯拉也经历了短暂的低谷和失落。
但在随后的日子里,失意的特斯拉最终成长为自动驾驶领域领头羊。
02
2016 年-2018 年
特斯拉初出茅庐
在告别了 Mobileye 之后,特斯拉选择全栈自研自动驾驶算法,自立自强。
在自动驾驶软硬件发展思路上,马斯克为特斯拉制定了「硬件先行,软件更新」的思路。
硬件方面,2016 年 10 月,特斯拉还发布了第二代硬件 Hardware 2.0。自动驾驶芯片由英伟达提供,配置 8 个摄像头+12 个远程超声波雷达+1 个前置毫米波雷达,并且这一套配置延续到了 Hardware3.0。
算法方面,特斯拉延用了业内常规的骨干网结构;使用 2D 检测器进行特征提取;以人工对数据进行标注。
整体来看,这一套自动驾驶算法还比较原始,相对传统。
值得一提的是,在这一时期,特斯拉自动驾驶算法仍处于技术追赶阶段。
从硬件配置来看,尽管 HW2.0 优于此前 Mobileye 提供的的 HW1.0,但受限于软件算法,彼时特斯拉的自动驾驶能力和 Mobileye 有着较大差距。
尽管2016 年 10 月,特斯拉推出了 HW2.0,但在空跑了大半年后,直到2017 年 3 月,Model3/Y 才开始能够真正用上 Autopilot 功能。
在算法能力追上 Mobileye 后,特斯拉发现,当前使用的算法存在着诸多不足。其中,最为明显的是效率问题。
在那一时期,自动驾驶的目标检测普遍遵循一个通用的网络结构:
Input → backbone → neck → head → Output
主干网络 backbone 为特征提取网络,主要用于识别图像中的多个对象;
neck 则主要负责提取更为精细的特征;
而在经过特征提取之后,检测头 head 则为提供了输入的特征图表示,比如检测对象,实例分割等。
值得一提的是,当时业内自动驾驶视觉神经网络都只有一个 head。
但是,在自动驾驶的场景中,往往需要在一个神经网络中同时完成多项任务,比如车道线检测,人物检测与追踪,信号灯检测等。
这就使得原有算法出现了「脑袋不够用」的情况。
因此,在 2018 年,特斯拉开始了对自动驾驶算法的第一次革新,瞄准自动驾驶网络结构及效率。
03
2018 年-2019 年
算法利刃初成
在这次算法革新中,特斯拉构建了多任务学习神经网络架构 HydraNet,并使用了特征提取网络 BiFPN。
这使得特斯拉算法效率得到了提升。其中,最具特色的为 HydraNet。
Hydra 一词源于传说中的生物「九头蛇」,因而 HydraNet 也被称为「九头蛇网络」。
以「九头蛇」命名的原因在于,HydraNet 结构能够完成多头任务,而非此前的单一检测。

相较于此前算法,HydraNet 能够减少重复的卷积计算,减少主干网络计算数量,还能够将特定任务从主干中解耦出来,进行单独微调。
不过,此次革新更多是一次算法的「微调」,并没有达到重构和跨越性的程度。
在融合方式上,特斯拉采用的仍是后融合策略,数据进行人工标注,且自动驾驶算法仍旧是小模型,与后续算法革新相比,并没有太大的突破。
这一时期,在改良了传统算法之后,特斯拉还对硬件进行了新一轮的更新。
在历经四年研发后,2019 年 4 月,特斯拉发布了 Hardware 3.0 系统。其中最大的亮点是特斯拉采用了自研的 FSD 芯片
特斯拉 FSD 芯片算力达 72TOPS,远高于当时市面上的自动驾驶芯片。同时,FSD 芯片以两块 NUD 为主,图片处理效率更高,且不装配激光雷达。
新硬件的发布,为特斯拉算法的下一次迭代提供了可能。
在完成硬件准备的前期工作之后,特斯拉开始了对自动驾驶算法的史诗级重构。
04
2020 年
特斯拉自动驾驶一骑绝尘
2020 年 8 月,马斯克在推特上发文称,Autopilot 团队正对软件的底层代码进行重写和深度神经网络重构;全新的训练计算机 Dojo 正在开发。
马斯克的一封推文激起浪千重。市场对特斯拉自动驾驶算法的发展方向投以关注。
在他看来,对 AP 的重写,不是对现有结构的优化,而是一场「量子式跃迁」。
纵览特斯拉自研算法近十年历程,2020 年可以说是其最为璀璨的一年。
在这一场行业重构中,特斯拉带来的一系列技术方向被自动驾驶行业延用至今,如 BEV+Transformer 的组合,特征级融合取代了后融合,数据自我标注取代人工标注等。
如果说 2020 年自动驾驶江湖是群雄逐鹿时期,那么,自 2020 年之后,这片江湖便进入了特斯拉时代。
(1)BEV+Transformer,自动驾驶进入大模型时代
在特斯拉的这场技术重构中,最为引人注目的便是于 2020 年引入的 BEV+Transfomer 架构。
在特斯拉看来,过去自动驾驶依靠「2D 图像+ CNN」便企图实现全自动驾驶是不太可能的。
主要原因在于,摄像头采集的数据是 2D 图像,但自动驾驶需要面对的却是三维真实世界。
以二维数据解决三维问题,不大现实。
纯视觉路线之下,摄像头拍摄的 2D 图像如何「升维」到 3D,成了特斯拉需要思考的问题。
在特斯拉看来,2D 图像「升维」的最佳表达方式是:BEV(鸟瞰图)。
BEV 视角,形成车身自坐标系的好处在于两方面:
一是将不同视角在 BEV 下统一表达是很自然的描述,有利于后续规划控制模块任务;
二是 BEV 视角解决了图像视角下的尺度和遮挡问题。
但紧接着问题就来了:如何实现 2D 向 3D 的转换,以引入 BEV?
2D 图像是照片,存在近大远小的问题。而解决「近大远小」问题的传统转变方法是依靠 IPM(逆透视变幻),进行先 2D 再 3D 的正向开发。
IPM,简而言之,就是利用照相机成像过程中坐标转换的公式,在已知照片的光圈,焦距等条件下,去「算出」3D 坐标数据,对 2D 的图像进行「3D 复原」。
但是,和课堂上的算数题一样,这样的计算需要以各种「完美」假设为前提。比如,地面是「完美」水平的,相机和地面不存在相对运动等。
也即是说,只要车辆有任何一点颠簸,道路有一点不平,就会打破这个假设,导致最终的成像结果失真。
另外,在一系列卷积,提取特征,融合之后,得到的感知结果,再投影到 BEV 空间中,精度很差,尤其是远距离的区域。
以此来看,利用传统方法,实现从 2D 到 3D 的「升维」,很难实现。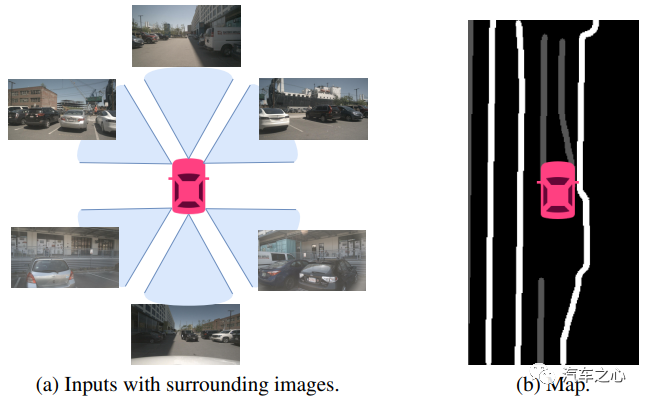
在这样的情况下,特斯拉引入大模型 Transformer,进行 3D 到 2D 的逆向开发。
在这一方式中,特斯拉先在 BEV 空间层中初始化特征,再通过多层的 Transformer 和 2D 图像特征进行交互融合,最终得到 BEV 特征,也就是先 3D 再 2D,反向开发,实现 BEV 的转换。
Transformer 是一种基于注意力机制(Attention)的神经网络模型。与传统神经网络 RNN 和 CNN 不同,Transformer 不会按照串行顺序来处理数据,而是通过注意力机制,去挖掘序列中不同元素的联系及相关性。
这种机制背后,使得 Transformer 可以适应不同长度和不同结构的输入。
Transformer 的引入,使得 BEV 视角在自动驾驶领域得以实现。
而 3D 空间的引入,使得自动驾驶的思维方式,更接近于真实世界。
但是,在这一阶段,BEV 空间仍是对瞬时的图像片段进行感知,缺乏时间序列信息,自动驾驶仍未进入 4D 空间。
(2)特征级融合取代后融合成为主流
BEV 即鸟瞰图,「上帝视角」,车身自坐标系。
若仅从定义来看,BEV 或许是特斯拉各类「烧脑」术语中最容易理解的。但这丝毫不影响 BEV 对自动驾驶行业的价值和意义。
引入 BEV 视角后,给自动驾驶带来最直观的变化是,推动 2D 图像向 3D 车身自坐标系的转变,方便后续的决策和控制。
但除此之外,BEV 还使得自动驾驶从后融合(或称「决策层融合」)向特征级融合(或称「中融合」)方向迈进。

同一物体在不同传感器视角中的状态
自动驾驶的每一个传感器,都在对周遭世界进行感知。
每个摄像头、雷达都包含了其对真实世界的理解,但由于角度,传感器类型的不同,使得车辆没办法依靠一个传感器完成对周遭世界的认识。
因此,每个传感器所感知的只是现实世界的其中一块拼图,要实现自动驾驶,便需要完成拼图拼凑。
而传感器数据的融合则可以看成是拼图的拼凑步骤。
所谓的后融合,便是由决策层域控制器进行拼图的拼凑。
后融合的好处非常明显,传感器「即插即用」,融合在域控制器决策层,对芯片算力要求较低。
后融合策略对车端算力要求仅在 100TOPS 以内,作为参考,前融合却需要 500-1000TOPS 算力。
而特征级融合介于两者之间,大约需要 300-400TOPS。
因此,在自动驾驶的早期,由于门槛低,后融合策略受到了自动驾驶供应商、车企的欢迎。
但是,后融合策略容易产生信息失真,造成错误决策。
后融合策略下,低置信度信息会被过滤掉,产生原始数据的丢失,并且可能误差叠加,导致信息「失真」。
尤其是在恶劣天气下,这样的情况更为明显。这就有可能造成决策层错误决策。
相较于后融合策略,特征级融合本质上更接近于传感器的原始数据。因此,其准确度必然会更高。
除此之外,在 BEV 空间层进行特征级融合,还具有多种好处,更是后续行业革新的方向:
跨摄像头融合和多模融合更易实现。大多数行业公司采用的是异构传感器(摄像头、激光雷达、毫米波雷达等)的感知方案。而 BEV 空间能够统一传感器数据维度,更容易实现特征融合。
时序融合更易实现。
可「脑补」出遮挡区域的目标。
更方便端到端做优化。
得益于此,BEV 架构也成了国内自动驾驶公司延用的基本方向。
(3)数据从人工标注转向自我标注
在自动驾驶圈,有一句名言:数据决定了算法的上限,模型只是不停的逼近这个上限。
数据燃料在自动驾驶算法训练中的地位可见一斑。
为了确保投喂给算法的数据正确而有益,过去自动驾驶行业往往都采取人工标注的方式。
特斯拉也不例外。
在 2018 年时,特斯拉选择和第三方公司合作,但这样的方式标注效率很低,并且沟通的成本很高。
为了实现标注效率和质量的提升,特斯拉自建了标注团队,人员规模一度超过 1000 人。

2D 图像的人工标注
但是,自建标注团队也随之带来了新问题。
随着自动驾驶数据的进一步扩大,所需的标注人员数量也在进一步增长,这意味着成本水涨船高。
鉴于高成本,低效率的属性,人工标注自然地成为了特斯拉的「眼中刺」。
在 BEV+Transfomer 引入后,特斯拉的数据标注效率得到了一定提升。在引入 BEV 空间层前,标注人员需要标记 8 张 2D 图像,而在 BEV 空间层下,仅需要进行一次 3D 空间中的标注便可完成。
但是,由于人类标注员对于语义信息更擅长,而计算机对几何,重建,三角化,跟踪更加擅长。
这使得 BEV 下,数据标注是一种「半自动」状态,需要人工和计算机进行协作。
同时,尽管标注的效率有所增加,但在数据的指数级增长下,仍旧捉襟见肘。
显然,自动标注才是效率、效果、成本三方矛盾的最终破局方法。
为此,在 2020 年开始,特斯拉研发并使用了数据自动标注系统。
特斯拉数据标注的思路非常简单:用更多的数据训练更大的模型,再用「大模型」的数据训练车端「小模型」。
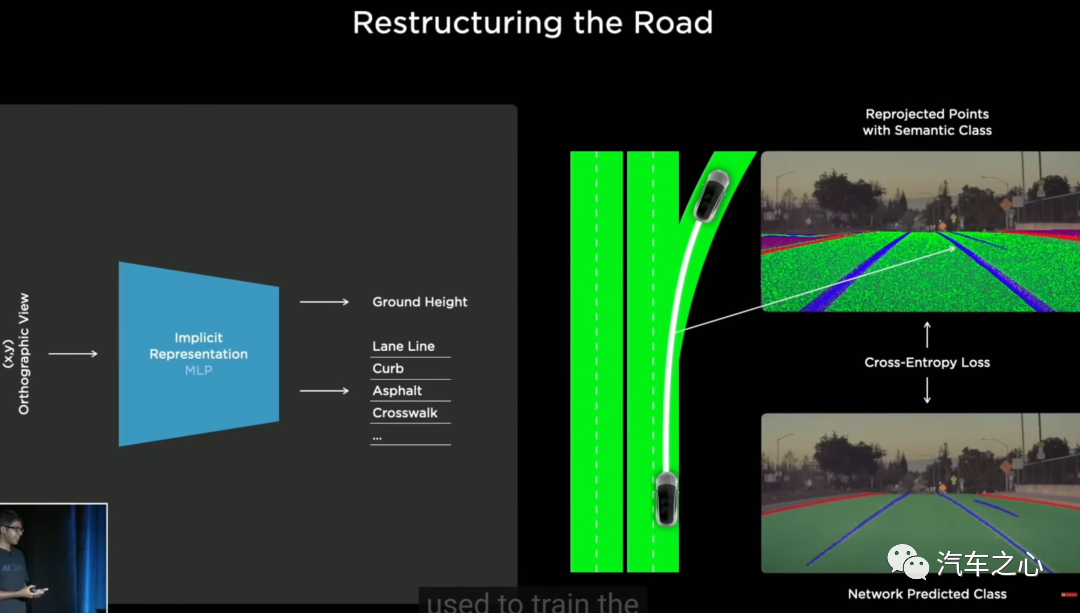
在车辆行驶过程中,摄像头收集的路面信息,打包上传到服务器的离线神经网络大模型,由大模型进行预测性标注,再反馈给车端各个传感器。
由于传感器视角不同,当预测的标注结果在 8 个传感器均呈现一致时,则这一标注成功。
而这一过程,也即是车载模型对服务器的大模型进行自动标注系统的蒸馏。

同时,车辆也在充当特斯拉「众包地图」采集车的角色。
当不同的车辆走在同一段路时,离线大模型将记录同一段路不同的标注结果。
当数据标注系统将不同车辆,不同时间,不同天气状况下的标注结果叠加后,得到了一个具备高度一致性的标注结果,这也意味着,特斯拉得到了自己的「高精地图」。
05
2021 年-2022 年
剑指端到端大模型
BEV+Transfomer 架构的引入,可以说是一场行业重构。
这一「黄金组合」在自动驾驶领域有着诸多优势,是过去算法所不具备的。
但是,BEV+Transfomer 在推出之初,也并非完美无瑕。
随着自动驾驶的进一步发展,面临场景逐渐多样化,coner case 越来越多,这便对自动驾驶算法的泛化能力提出了新的要求。
在随后的两年时间里,为了让算法更接近人类的思考方式,特斯拉对 BEV+Transformer 架构进行了改良。
其中,最主要的两个改良是时序信息的增加和占用网络的应用。
虽然 2020 年,特斯拉利用 BEV 解决了 2D 向 3D 转换的空间问题,但却仍未引入时序信息。
也即是说,在上一个版本中,BEV 仍然是对瞬时的图像片段进行感知,缺乏时空记忆力,汽车只能根据当前时刻感知到的信息进行判断。
时序信息的缺席,让自动驾驶潜藏了极大的安全风险。
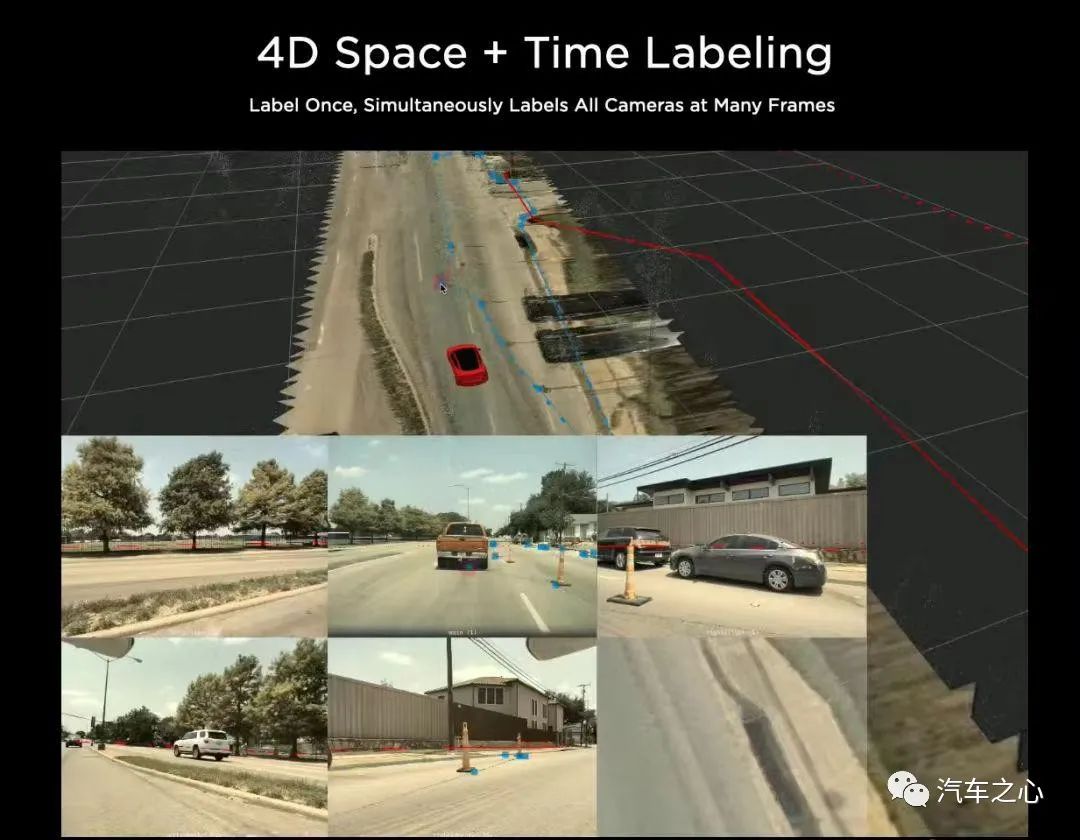
例如在行车过程中,如果有行人正在穿过马路,过程中被静止的障碍物遮挡,如果汽车仅有瞬时感知能力,由于在感知时刻行人正好被汽车遮挡,则无法识别到行人,可能威胁驾乘人员和行人的安全。
人类司机在面对类似场景时,则会根据之前时刻看到行人在穿越马路的记忆,能够意识到行人被车辆遮挡,且有继续穿越马路的意图,从而选择减速或者刹车避让。
如何给自动驾驶增加「记忆」功能便显得尤为关键。
因此,自动驾驶感知网络也需要拥有类似的记忆能力,能够记住之前某一时间段的数据特征,从而推演目前场景下可能性最大的结果,而不仅仅是基于当前时刻看到的场景进行判断。
为了解决这一问题,特斯拉感知网络架构引入了时空序列特征层,使用视频片段,而不是图像来训练神经网络,为自动驾驶增添了短时记忆能力。
除了引入时序网络外,在 2022 年,特斯拉对 BEV 进行了升级——引入占用网络。
在过去,自动驾驶算法和人作比较,往往显得呆板、过于机械。
在传统的自动驾驶算法中,大多是依靠大数据喂养,得出「经验」,然后识别物体,再进行决策。
也即是说,算法需要经历,感知,辨识,决策,执行这样的思考流程。
但在现实世界里,真实的路况下,实际情况是错综复杂的,存在着大量的极端情况(corner case),要让算法认全所有事物,显然不太现实,且效率不高。

以「二仙桥大爷」为例,若自动驾驶遇上了如此「超载」的车辆,算法将其识别为一般的三轮车,并判断路况,但对车后拖载的货物,既不显示,也不识别。
当自动驾驶的车辆进行超车变道时,就容易发生剐蹭等事故,潜藏一定风险。
为了解决这类问题,特斯拉将 BEV 升级到了占用网络(occupancy network)。
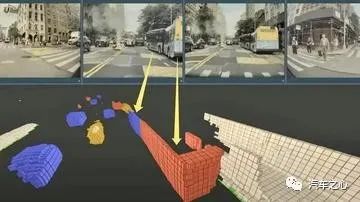
在 2D 图像世界中,一个物体由无数个像素点组成。
而在占用网络之下,3D 的真实世界则是由无数个微小立方体——体素堆叠组成。
占用网络,将原本的 BEV 空间,分割成无数的体素,再通过预测每个体素是是否被占用。
简单来说,不考虑这个物体到底是什么,只考虑体素是否被占用。这使得非典型但却存在的事物能够直接表示出来,增加了算法的泛化能力和对现实世界的认知。

实际上,占用网络的体素,充当了激光雷达点阵的作用。而占用网络最直接的效果便是实现了「伪激光雷达」的效果。
时序信息的增加,升级占用网络,使得特斯拉自动驾驶算法的泛化能力得到了提升。
而借助于算法提升,特斯拉 FSD 更能刻画真实的物理世界,进而才有可能实现端到端模型。
06
未来,自动驾驶将走向何方
在自动驾驶领域,特斯拉毫无疑问是领头羊。
在确定纯视觉路线后,特斯拉在自动驾驶算法上进行了四次迭代更新。除了第一次是为追赶行业发展以外,其余更新均引领行业的发展。
特斯拉能够走在行业前列,除了优秀的团队以外,更在于整体的思路设计秉持「第一性原理思维」。
所谓的「第一性原理思维」,即一种刨根问底、追究最原始假设和最根本性规律的思维习惯。
「物理学教会你根据第一性原理做出推理,而不是通过类比进行推理。类比式推理就是几乎丝毫不差地模仿或模拟他人。」马斯克曾如此说到。
在特斯拉自动驾驶迭代思维上,第一性原理思维渗透在了方方面面:
计算效率不高,HEAD 部分不够用?开发了九头蛇网络结构;
小模型无法实行并行计算,泛化能力不强,BEV 无法精确实现?引入大模型 Transfomer,逆向开发;
现有芯片的构成冗余,不适配纯视觉路线需求,且成本高?自研 FSD 芯片;
数据标注成本高,数据训练量不足?建设超算中心 DOJO,实现数据自我标注,同时虚拟场景训练算法,提高自动驾驶能力等等。
在锚定纯视觉路线后,特斯拉均在算法迭代中,针对各种问题,发现短板,并加以解决。
而这,正是特斯拉执牛耳的关键。
同时,鉴于特斯拉的行业领导地位,研究其自动驾驶算法迭代历程后,也能让外界窥见自动驾驶行业的未来。
(1)「轻地图,重感知」成行业主流方向
在过去,自动驾驶行业,往往采取高精地图方案,辅助实现自动驾驶。
高精地图能够提供超视距、厘米级相对定位及导航信息,在数据和算法尚未成熟到脱图之前,能够成为整机厂的「拐杖」,帮助自动驾驶的落地。
但是,和其优点一样,高精地图的缺点也非常明显:
需要图商采集更新,无法实时更新;
制图资质受到严格管理,信息采集面临一定法规风险;
成本昂贵高昂。
在这样的情况下,特斯拉构建了自己的「高精地图」。
通过 BEV 空间层,特斯拉将不同视角的摄像头采集到 2D 图像统一转换到 BEV 视角,车辆形成自车坐标系。
同时,引入服务器的离线神经网络,实现数据自动标注,确保标注效果,且在无数「众包采集车」的帮助下,叠加标注结果,得出道路信息标注的「唯一解」。
BEV、Transfomer、引入时序信息、数据自动标注等等,一系列技术加持之下,特斯拉才得以实现「无图」。
国内市场,「轻地图,重感知」也成为了行业发展的主流方向。
2022 年 4 月,毫末智行提出要做「重感知、轻地图」的城市智能驾驶,开始降低方案中高精地图的权重,乃至做到无需高精地图;
2022 年年底,小鹏发布了第二代智能辅助驾驶系统 XNGP,并对外宣布将摆脱高精地图限制;
2022 年下半年,华为余承东表示:
「自动驾驶未来不应过分依赖于高精地图、车路协同。」
今年 5 月,蔚来发布了 Banyan 2.0.0 系统,完成了向 BEV 感知路线的切换;
国内一众厂商深受特斯拉路线影响,延用 BEV 架构,开始对高精地图动刀,「重感知,轻地图」路线成为了市场主流发展方向。
特斯拉的 BEV+Transformer 方案为行业的「脱图」提供了技术上的可行性。
从特斯拉路线经验来看,如果要以纯算法,实现摆「脱图」,或许需要车企同时具备以下两个条件:
引入 BEV 架构,实现异构传感器的融合,生成活地图;
具备超算中心,或离线服务器的大模型,能够实现自动标注及仿真训练;
目前,「轻地图」路线大多仍是通过软硬件结合的方式,降低高精地图需求,本质上仍然是「多传感器+高精地图」路线。
从行业发展趋势来看,国内车企也在向「云端大模型+BEV」的路线靠拢,以期实现「脱图」。
6 月 17 日,在理想汽车家庭科技日上,理想副总裁兼自动驾驶负责人郎咸朋便对外公布了理想汽车的 NPN 网络。
郎咸朋介绍称,在车辆行经一段路时,NPN 网络将道路信息特征进行提取后,存储于云端。
而当车辆再次行驶到该路口时,再将储存的道路特征拿出来,与车端模型进行特征层融合,以此解决道路信息的遮挡问题。
当 NPN 网络对同一路段堆叠大量标注结果后,最终便达到了「高精地图」的效果。
理想汽车的「NPN 网络+BEV」实际上延用的就是特斯拉的「离线大模型+BEV」的技术路线。
(2) 升级到占用网络,实现去「激光雷达」
在 2022 年的 AI day 上,特斯拉将 BEV 升级到了占用网络。
占用网络显著的特点是,抛弃了过去算法需要先识别、判断物体,再进行决策的思路。
在面对训练中没有出现过的物体时,如侧翻的白色大卡车,垃圾桶出现在路中央,传统视觉算法是无法检测的。
而占用网络,则用体素的概念,仅仅是判断该空间有没有物体,而不去深究物体是什么。
这大幅提升了模型的泛化能力,有助于城市 NOA 的实现。
从特斯拉 AI Day 演示效果来看,特斯拉通过鸟瞰图、占用检测和体素分类使纯视觉方案已经达到「伪激光雷达」效果。
值得注意的是,在特斯拉发布的最新硬件 HW4.0 中,预留了 4D 毫米波雷达接口。这预示着特斯拉或将重启毫米波雷达,以弥补纯视觉算法在高程信息感知上的不足。
从成本来看,公开报道显示,4D 毫米波雷达价格仅约为高线束激光雷达的 1/10。
(3)AI 大模型卷入自动驾驶,超算中心成标配

今年 5 月,马斯克发推文称,FSD11.透露称,FSD V12 版本将完全实现端到端。
什么是端到端?
目前,自动驾驶模型架构将驾驶目标分为感知、规划、控制三大模块。
但是,这和人类驾驶行为有着根本的不同。
人类司机在看到视觉信息后,不会对所看到的物体进行数据分析,而是基于经验,在「黑盒」状态下完成驾驶决策,并协调手、脚执行任务。
而端到端模型更为贴近人的驾驶决策行为。
摄像头采集到外界的视频数据后,算法直接输出的是方向盘转角多少度的控制决策,不存在单独的「图像识别检测」任务。
端到端模型的决策在「黑盒」状态下进行,通过赋予数据,使算法积攒「经验」,使得其决策和执行同步进行。
在理想状态下,「黑盒」状态下的端到端大模型实际比基于规则设定的传统小模型更为安全。
比起传统的设定规则,参数对算法结构进行「补丁」式矫正,只要投喂的正确案例足够多,那么 AI 大模型模型所需要的时间必然小于传统规则。
而经过足够的数据和案例的投喂,端到端模型的泛化能力也必然强于传统的自动驾驶算法。
为了使得大模型落地,海量的数据投喂成了厂商必然选择。
毫末智行 CEO 顾维灏就曾公开表示,要使由数据驱动的 Transformer 大模型量变引起质变需要 1 亿公里的里程数据。
这一海量数据显然无法单独依靠某个厂家通过销售车辆完成。在这样的情况下,超算中心便成了 AI 大模型落地的标配。
超算中心对大模型的助力主要体现在数据标注和仿真训练上。
特斯拉 2022 年发布的超算中心 Dojo 便是如此。
特斯拉 Dojo 的功能,能够利用海量的视频数据,做「无人监管」的标注和仿真训练。

特斯拉打样在前,国内不少厂商也紧随其后。在 2022 年以后,超算中心开始活跃在自动驾驶领域。
2022 年 8 月,基于阿里云智能计算平台,小鹏推出了扶摇超算中心,每秒浮点运算达 60 亿次,专用于自动驾驶模拟训练。
同时,小鹏还推出了全自动标注系统,将标注效率提升近 4.5 万倍,以前 2000 人一年的标注量,现在 16.7 天可以完成。
今年 1 月,毫末智行和火山引擎联合打造了 MANA OASIS 智算中心,用于自动标注及仿真训练。
据悉,MANA OASIS 智算中心,每秒浮点运算达 67 亿次,存储带宽每秒 2T,通信带宽每秒 800G。
除了小鹏和毫末以外,跟随特斯拉步伐,国内车企设立的超算中心还有:吉利设立了星瑞智算中心;智己汽车的云上数据超级工厂等。
可以说,在自动驾驶领域,特斯拉引领着行业的发展方向。
自 2020 年以来,特斯拉率先使用了 BEV、Transfomer 架构、离线网络大模型,随后,国内众多车企才开始纷纷跟进。
而近一段时间,「FSD 入华」的话题时常引发市场讨论。
在热议的背后,有观点认为,FSD 将是那条引起自动驾驶行业优胜劣汰的鲶鱼。言外之意满是对行业赛道参与者的担忧。
这倒也不用过分忧虑。
正如前文所言,特斯拉也并非一开始就是「江湖第一」。
在经历「被分手」后,特斯拉自动驾驶算法经历了落后,到追赶,再到引领的不同时期,更多是带有逆袭成分。
而逆袭的关键点在于:选好目标,敢于「一条道走到黑」。
在过去一段时间里,市场对于特斯拉的纯视觉方案并不看好。不少业内观点认为,激光雷达是安全件,纯视觉方案的自动驾驶并不具备可行性。
但在确定纯视觉路线以后,针对纯视觉方案的各种问题,特斯拉从第一性原理出发,思考确切问题的根本,并提出解决方式。
最终的结果是,特斯拉成为自动驾驶领头羊。
目前,自动驾驶也并未到决赛阶段。对于国内这一赛道的参与者,市场要有足够信心。
毕竟,特斯拉 FSD 仍未入华,而赛道参与者的较量仍未真正开始。
0
分享
好文章,需要你的鼓励













参与评论
请您注册或者登录汽车之心社区账号即可发表回复
去登录
相关评论(共0条)
查看更多评论