
端到端自动驾驶:谁在 All in,谁在观望

作者|安富建
「『端到端』并非灵丹妙药。」
乍看之下,蔚来 AI 平台负责人、资深研发总监白宇利这一观点,容易让外界产生蔚来动摇对端到端路线的误会。
实际上,这是蔚来方案的重申。蔚来计划是把规划和控制的代码模型化之后,再做更具整合性的「端到端」大模式。
目前,小鹏、理想、蔚来的「端到端」大模式路线,都是类似「散装」——「打散了重装」——「端到端」大模式。
6 月 8 日,在 2024 中国汽车重庆论坛上,理想汽车董事长兼 CEO 李想发表了关于自动驾驶技术路线的新思考:
「端到端+VLM(视觉语言模型)+生成式的验证系统,会是未来整个物理世界机器人最重要技术架构和技术体系。」
李想认为不能依赖端到端解决 corner case,而是要提升能力。用视觉语言模型即 VLM,让车面对路口、红绿灯等能够及时作出反应。
作为「国内首个端到端上车」的车企,5 月 20 日,小鹏汽车宣布上车的端到端大模型由三部分组成,分别是神经网络 XNet(侧重于感知和语义),规控大模型 XPlanner 和大语言模型 XBrain(侧重于整个大场景的认知)。
小鹏、理想、蔚来的策略,有别于特斯拉提出的借助完全依赖神经网络处理的「端到端」大模型,解决 corner case——神经网络只是一个环节。
说起来,国内智驾行业论坛聊起来都没人知道,特斯拉到底是怎么做到的。
「没有任何人敢说端到端都是神经网络。」在「端到端」发布会后,何小鹏接受媒体采访时表示,「它是在一个体系里面完成的,就像刹车在哪里,它一定是有规则体系的。我们在规则体系里面有一个优势,能够把刹车控制器的算法沙盒做好。」
英伟达汽车事业部副总裁吴新宙认为,端到端正是智驾三部曲的最终曲。
面对终局之战,今年 2 月,特斯拉端到端大模式启动商业化孩子会,前后几家新势力代表的车企立下「端到端」上线时间表。
2024 年过去了一半,今年能否成为端到端上车「元年」?
从国内的小鹏率先上车端到端大模式,回溯到「古典主义」端到端大模式的特斯拉,要攻下端到端堡垒,国内车企应该怎么走?绘制一张从学界到业界完整端到端大模型的图谱,或许能够让人们找到车企在其中的位置。
01
小鹏之后,
下一个「端到端」智驾规模化量产是谁?
2023 年 8 月,特斯拉 FSD V12 版本问世,成为首家成功量产「端到端」架构的车企。
今年 2 月,特斯拉将基于端到端架构的 FSD V12 版本向部分普通用户推送,启动商业化落地。
FSD V12 的流畅性、令人惊艳的体验感,初露锋芒。
2024 年 5 月,小鹏宣布「端到端」架构上车。
整体来说,以车企为代表,「端到端」有三大派:整车厂、自动驾驶企业、学术机构。学界和工业界一些切入「端到端」大模式甚至早于特斯拉。
车企方面,蔚来、理想、小鹏、小米、极越、智己、广汽、长城、极氪等,成为国内第一批公开行动或表态者。
近期,蔚来单独设立了一个大模型部,专门负责端到端的模型研发,由原感知部门和规控部门下的模型部合并而来。
调整后,蔚来智驾的核心业务,分为「云」(大模型部)和「车」(部署架构与方案部)两块,取消原来按照功能(感知、地图、数据、规控等)模块划分的方式。
「云」负责创造出更好的基础模型,去支持未来「车」端的迭代。
「云」,意味着迅速打破算力瓶颈的可能。
目前,蔚来打通了边缘计算的能力,车云算力联合调度,在蔚来整体端云上的算力,有 287.1 EOPS,相当于 100 个分布式的千卡训练集群,「这基本和特斯拉的 10 万片 H100 的算力规模差不多。」
蔚来采取的是渐进式「端到端」大模型技术路线。
蔚来智能驾驶研发副总裁任少卿认为,做端到端大模型的前提是智驾各功能模块都已经完成模型化,且足够性能与效率的工程体系支撑,「大家没办法模型化,很多时候是因为你的工程体系支撑不了这件事」。
比如,需要有快速训练一个模型再快速验证的能力,「你这个事儿才玩的下去」「你得有一些基本的能力之后,(端到端大模型)这玩意才有用,否则它是个毒药。」
2023 年年底,理想在「算法研发」团队下也为端到端模型单独成立了一个团队。
算法研发除了要负责端到端模型的研发,也要负责三季度无图城市 NOA 的量产。
目前,理想正在做端到端架构的封闭开发:端到端+VLM(视觉语言模型)+生成式的验证系统。
「最早在今年年底,最晚在明年上半年,真正有监督的 L3 自动驾驶就可以批量向用户交付了,而不是做实验。」而且,「L4 级别无监督的自动驾驶在三年内一定能够实现。」李想表示。
此前,理想汽车与清华大学交叉信息研究院一直在进行联合研究。
今年 2 月,双方团队联合发布了论文《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》。
小鹏的端到端大模型,据说未来能实现 2 天一次迭代,未来 18 个月智驾能力提升 30 倍。
有别于外界以前觉得端到端 AI 大模型就是一个大的网络,小鹏汽车智能驾驶技术负责人李力耘表示:
「我们对 AI 的认知也提出了 XBrain、XNet、XPlanner,既有联系又有分工,能够非常好地提升 AI 智驾能力上限。」
这是小鹏真正去量产端到端大模型的一个重要原因。
除了「蔚小理」,还有几家态度比较明确。
去年 12 月 28 日,雷军在小米汽车发布会上宣布:「小米汽车首次运用自研的『端到端』感知决策大模型」,并称这是全球首次应用于量产车。图森未来的前 CTO 王乃岩加入小米智驾团队,王乃岩曾指出,从业者不能被特斯拉「带偏」,陷入到狭义的端到端理解中。
极越 CEO 夏一平表示,「下一步研发重点将是端到端大模型」。
智己汽车联席 CEO 刘涛称,「目前智己汽车也正在全力推动『端到端』架构落地,创造『更像人』的智能驾驶体验」。目前,智己正和 Momenta 合作,推动端到端智驾大模型量产落地。
广汽研究院也表示正在探索「端到端」自动驾驶方案,「并取得初步成效」。
长城(毫末智行)在去年 4 月发布自动驾驶生成式大模型「雪湖·海若」时表示,将对自动驾驶认知决策模型进行持续优化,最终实现「端到端」自动驾驶。现阶段主要用于解决自动驾驶的认知决策问题。
一些车企采取了比较谨慎的态度,比如极氪。极氪内部认为「在数据量不充分、安全性难以保证的当下,更多将『端到端』技术路线作为预研项目」。
整体来说,大部分车企和极氪类似,认可「端到端」的发展趋势,行业转向『端到端』架构的方向非常明确。
二是智驾供应商,已经有多家发出比较坚定的技术转向的声音,并有方案正在推出。目前,包括华为、Momenta、元戎启行、商汤绝影等国内头部企业已经公开端到端自动驾驶方案在 2024-2025 年上车的规划。
三是学术界方面,以上海人工智能实验室,跨界合作的华中科技大学(与地平线合作)和南洋理工大学(和英伟达合作)以及剑桥大学工程系团队创办的 Wayve 等为代表,推出多篇优秀论文。
上海人工智能实验室的自动驾驶全栈可控「端到端」方案 UniAD 相关研究,获得人工智能顶会 CVPR(国际计算机视觉与模式识别会议) 2023 年最佳论文,是「端到端」架构最受关注的项目之一。
今年 2 月,华中科技大学、地平线共同发布了《VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning》,提出 VAD v2「端到端」自动驾驶模型,一个基于概率规划的「端到端」驾驶模型。
此外,南洋理工大学和英伟达也合作提出了一个新框架。
实际上,早在几年前英伟达已经在使用「端到端」深度学习,并开发出了无人驾驶的 Demo 系统。
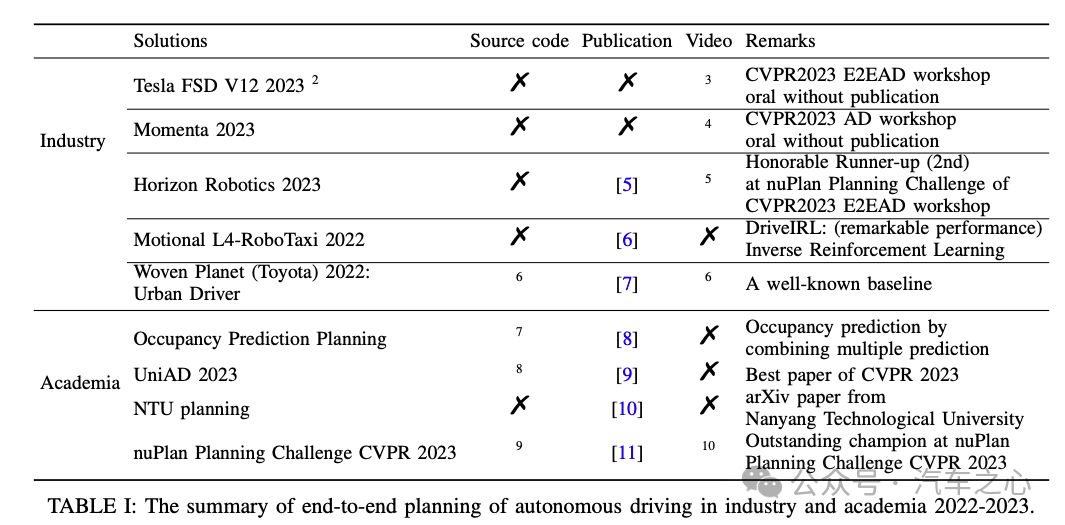
署名作者 Gongjin Lan、Qi Hao 近期发布论文《End-To-End Planning of Autonomous Driving in Industry and Academia: 2022-2023》梳理2022 年-2023 年工业界和学术界中的自动驾驶「端到端」规划(左侧栏为各公司及研究机构项目)
「端到端」的出现是相关技术长期积累的结果,但仍处于上车的初级阶段。
应对长尾问题(corner case)的能力更强,不少车企或许都能实现,但是在这背后容易忽视的是「端到端」大模型系统实现所要付出的成本。
02
大模型之后,
「端到端」走向高端&低端?
「端和端」架构正在分出不同的发展脉络。
在特斯拉 FSD V12 中,靠神经网络模型完成的落地效果已经收到不少追捧声音。
由于不再需要用于设置规则的具体指令,特斯拉工程师删除了 30 万行定义驾驶规则的 C++代码。
曾备受关注的上海人工智能实验室的自动驾驶全栈可控「端到端」方案 UniAD 的提出者李弘扬,在 2021 年注意到自动驾驶系统开源项目 Openpilot,一个「端到端」的系统设计。
相比特斯拉,他惊叹于 Openpilot 低成本实现的良好效果,并感慨:原来自动驾驶可以做得如此简单。
这是他开启 UniAD 研究的一个关键节点。
同样是「端到端」,如果说特斯拉的「端到端」是高「端」,那么李弘扬相关的这种低成本「端到端」可谓之低「端」。
这个对比或有不恰当之处,但是仍然极具阐释力:
在高「端」到低「端」之间,「端到端」架构可以分出来具备不同特征、实现效果存在差异的多个技术流派。
在自动驾驶行业,对「端到端」自动驾驶作评估有两类办法:
一是闭环评估和开环评估——这是每个端到端架构未来都要面对的专门测试。
闭环评估可以接受到反馈信号从而形成反馈闭环;开环评估则是分模块进行,并和真实数据作对比。比如,UniAD 在开环评估中得到验证,但是尚未在闭环评估中得到验证。
那么,哪家的「端到端」效果最好?如何用一个简单指标来衡量端到端大模型的有效性?
何小鹏说,对于端到端大模型的硬指标,最终看接管率。今天高速如果没有续航的问题,可以做到 1000 公里接管一次。
在城区,今天所有的城市辅助驾驶,我认为安全接管可能是百公里或者一两百公里。但体验接管是十公里以内。
如果在城区开 100 公里、300 公里、500 公里接管一次,体验完全不一样。
可以对比的是,特斯拉应用端到端神经网络架构的 FSD V12 的平均接管历程从此前的 166 英里(约 267 公里)提升到了 333 英里(约 537 公里)。
「端到端」的实现,与 BEV+Transformer 模型关系十分密切。
车辆在感知模块产生 BEV(Bird『s-eye-view),即鸟瞰图视角,始于 2014 年的一篇论文(《「Automatic Parking Based on a Bird』s Eye View Vision System》)。
Transformer 模型则是 2017 年时 Google 提出的。
2020 年前后,Transformer 模型被引入到智驾领域,特斯拉率先将 BEV 与 Transformer 结合在一起。
在 2021 年底至 2022 年间,BEV 与 Transformer 实现深度融合,通过 Attention 机制,感知模块和预测模块可以通过神经网络做到「端到端」的优化。
在感知、预测、规划、决策的分模块的算法中,主要用于感知模块的 BEV+Transformer 范式可以有效提升了感知精确度,能够将感知模块和预测模块在统一的 3D 空间中实施,通过神经网络直接完成「端到端」优化。
这直接促进了智驾的进一步 AI 化。
从感知、预测,深入至完全的「端到端」自动驾驶框架,最终可以用神经网络模型全部替换此前的规则代码——这就是特斯拉古典式的「端到端」大模式。
BEV+Transformer 模型规模化落地,也是今天「端到端」有可能迅速成为现实的一大原因。
但是,对「端到端」怀疑的声音一直存在。
早在 2016 年,Momenta 创始人曹旭东在回复「无人驾驶『端到端』的学习(end-to-end learning)是否靠谱?」时指出:
「对于无人驾驶,『端到端』不适合开发实用无人驾驶系统,可以做 Demo,然而大规模商用却非常困难」。
当时曹旭东否定「端到端」的原因有三点:
一是「不聪明」。「端到端」会产生「大量冗余数据和计算」。与之对比,如果把整个无人驾驶拆解成感知、地图、决策三部分,分别独立学习再融合,可以大大降低需要的数据和计算。
二是「不灵活」。在作一些系统调整后,收集数据学习的过程,往往需要推倒重来。
三是「难理解」。相比模块化,「对于整体『端到端』学习,一旦出现问题,因为无法对症下药」,即「黑箱」难题。
时隔多年,这些问题今天也或多或少仍然存在。
不过,当时他也坦诚,「我并不是完全否定『端到端』学习,而是无人驾驶『端到端』学习目前存在以上问题,或许在将来可以得到解决。」
时至今日,曹旭东对「端到端」的态度完全转变,Momenta 成为最看好「端到端」落地的积极派中的一员。
这个案例,正是「端到端」近年在自动驾驶领域内境遇变化的最好展现。
几年过去了,自动驾驶技术脉络也从模块化走到了神经网络。「端到端」的面世,时候到了。
03
AI 引领革命,
打赢「端到端」之战核心靠算力?
刺激 2024 年 2 月至年中「端到端」这波话题走高,源于特斯拉 FSD 12.0 版本开启推送,以及 Sora 的大火。
Sora 是基于「端到端」的 Transformer 来实现的。
而它生成视频像素的能力,是解决「端到端」自动驾驶问题的关键。
「端到端」自动驾驶训练的核心是视频生成。
因此,Sora 富有质感的视频,一定程度证明「端到端」路线的正确性。
特斯拉 CEO 马斯克自信地对外称:
「特斯拉拥有世界上最好的现实世界模拟和视频生成能力」。
「特斯拉在大约一年前就能以精确的物理生成真实世界的视频」。
与此同时,他也指出:
「我们的 FSD 训练算力不足,所以还没有使用其他的视频(所有的训练数据都来自汽车)进行训练,但当然是可行的。今年晚些时候,当我们有空余算力时,就会进行训练。」
实际上,算力难题一直存在。
2023 年 8 月,马斯克指出,FSD AI 的实现进程「眼下的限制因素在于训练的算力,而非工程师人力」。
算力的稀缺和昂贵,已经成为制约 AI 发展的核心因素。
国内发展「端到端」,首先要考虑提升算力的实力。
从大模型之战开始,囤算力成为各家行业公司的基本操作。
2022 年 8 月,阿里云宣布正式启动张北超级智算中心,当时号称「全球最大的智算中心」:总建设规模为 12EFLOPS(每秒 1200 亿亿次浮点运算)AI 算力,超过谷歌的 9EFLOPS 和特斯拉的 1.8EFLOPS。
同年 8 月 2 日,小鹏汽车宣布和阿里云合作在乌兰察布建成当时中国最大的自动驾驶智算中心「扶摇」。
「扶摇」算力可达 600PFLOPS(每秒浮点运算 60 亿亿次),将小鹏自动驾驶核心模型的训练速度提升了近 170 倍。
以最新公布的车企与智驾供应商的算力情况作对比:
特斯拉:截至 2023 年 8 月,算力达到 10 EFLOPS(预计 2024 年 10 月,Dojo 智算中心算力可达 100EFLOPS)。
理想:截止 6 月,训练平台算力达 2.4EFLOPS。
长安:最新披露,1.42EFLOPS。
蔚来:2023 年 9 月,智算集群总算力规模为 1.4EFLOPS。
极越:2 月最新数据显示,其算力在 1.8-2.2EFLOPS 范围之内。
吉利:2 月和阿里云成立「星睿智算中心」,计算能力达到 810PFLOPS。
长城:1 月毫末智行和火山引擎合作「雪湖·绿洲」智算中心,称其算力达 670PFLOPS。
小鹏:最新披露,600PFLOPS。
华为:最新披露,3.5EFLOPS。
商汤绝影:12EFLOPS(2024 年底将达到 18EFLOPS。)——这也是国内已知的用于自动驾驶训练的最大算力。
在华为全联接大会 2023 期间,华为发布昇腾 AI 计算集群 Atlas 900 SuperCluster,并表示:「中国一半大模型的算力都是由华为提供」。
即便如此,若特斯拉如期达到最新算力目标,国内智算中心的算力都将滞后。
从 10 EFLOPS,再到下一步计划的 100EFlops,特斯拉正在以 5 到 10 倍的增速实现算力扩张。
今年 2 月,特斯拉增加了 5 亿美元投资在超算中心 Dojo,值得注意的是,特斯拉的人形机器人业务 Optimus 也将通过 Dojo 训练。
当特斯拉已经在训练「端到端」大模型时,国内车企及自动驾驶企业才刚起步。
6 月 4 日,马斯克发推特表示,特斯拉买了 10 万片卡,在德州的工厂上扩展了一个数据中心,放了 5 万片卡进去。
那么,在国内要做端到端大模型,需要多少量级的「卡」(大算力 GPU)?
特斯拉的 DOJO 智算中心,预计到 2024 年 10 月,总算力将达到 100EFLOPs(10 万 PFLOPS),相当于约 30 万块英伟达 A100 的算力总和。
以小鹏「扶摇」自动驾驶智算中心为例,算力可达 600PFLOPS(以英伟达 A100 GPU 的 FP32 算力推算,约等于 3 万张 A100 GPU)。
100 张大算力 GPU 可以支持一次端到端模型的训练。大部分研发端到端自动驾驶的公司目前的训练算力规模在千卡级别(100 张 A100)。
毫末智行表示,要实现全国都能开,2000-5000 张 GPU 已经足够。
整体来说,尽管和特斯拉存在较大差距,但是国内车企到 2024 年底实现算力的倍数级增长,并非没有可能,并且能够接近 1~2 年前的特斯拉。
数据、算力、算法,人工智能发展的三件套,仅算力一项,就可能让各大车企或自动驾驶企业拉开距离。
国内车企并不悲观。
夏一平曾表示,「特斯拉虽然有一定领先,但极越在中国的落地能力一定更强」。
同样是纯视觉路线,极越已经进化至占用网络阶段,确实更了解中国更加复杂的路况等,从数据积累的环节已经和特斯拉在走分岔路。
眼下,城市 NOA 的落地仍是眼下竞争的主战场。城市 NOA 的刺激,「端到端」的落地,让国内车企及智驾供应商拿出各自新方案,同台竞技,决出胜负为时不远。
0
分享
好文章,需要你的鼓励













参与评论
请您注册或者登录汽车之心社区账号即可发表回复
去登录
相关评论(共0条)
查看更多评论